Kubernetes Resource Management
I had the chance to listen to Bekir Doğan’s presentation, a former Kartaca employee, at an event in 2017. I was very impressed when I heard that they set up and distribute all the services they manage with OpenVZ in containers in 2005. Was anyone really into this type of thing?
Apparently, yes. Since the early 2000s, most of the industry and the Linux community have been trying to make containers into what they are today. In particular, Google has been a pioneer in making containers mainstream with its contributions. You might have thought of Kubernetes right away, but this time I’m talking about cgroups technology.
A brief introduction to cgroups
It is easy to mistake a container for the entire system’s sole owner since it isolates a group of processes and runs on the same core with other containers and applications instead of virtualizing the whole system. An aggressively resource-consuming container can also destabilize the fellow containers, making the system unstable.
To prevent this, we can allocate the entire system to a container using virtualization, but this will waste resources most of the time. For example, in Borg’s design documents, maximum utilization of resources is stated as one of the project’s main objectives.
At this point, cgroups comes into play.
Google engineers started developing cgroups in 2006, and it was included in Linux 2.6.24 in 2008. It is a disruptive feature that shaped the ecosystem with the domino effect it creates.
With the inclusion of the code in Linux, system administrators can group the system’s processes/tasks and subject them to common constraints. Process priorities and resource limits can be configured and included in the accounting. Moreover, this kernel capability paved the way for software that radically changed system management such as LXC and later Docker.
Here is a small cgroups demo for you:
To summarize the demo;
- We create a control group called
fibtest. - Within the group we create, we run a small C application called
fibtest. This application generates Fibonacci sequences continuously. - With systemd-cgtop, we monitor resource consumption in all groups in the system.
- The real story starts here. Inside the group, we change two values:
cpu.cfs_period_usandcpu.cfs_quota_us. While determining how many microseconds each CPU period will last (50000) withcfs_period_us, withcfs_quota_us, we determine the maximum number of microseconds the program can use in each period (1000). Long story short, we choke the program. - We take back the values, and
fibtestbreathes again.
You can also get the cgcreate and cgexec tools we used in the demo by
installing cgroup-tools in Ubuntu 18.04, and libcgroup-tools in Fedora 32.
Kubernetes and cgroups
By default, system programs and containers run competitively on the machine resources. The containers’ resource consumption can make the machine unstable if no resources are allocated for system operations.
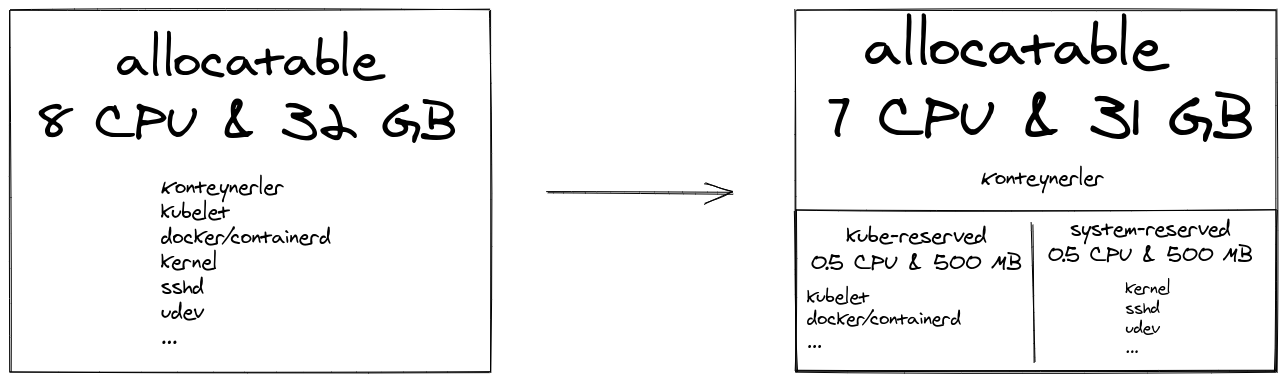
Kubernetes also provides resource isolation for system and user processes with cgroups. A cgroup called kubepods is created on every machine (if it doesn’t already exist). For the Kubernetes system and services, the cgroup is not created automatically; system administrators need to reconfigure kubelet.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
systemReserved:
cpu: 500m
memory: 500M
kubeReserved:
cpu: 500m
memory: 500M
$ kubectl describe node
...
Capacity:
attachable-volumes-gce-pd: 127
cpu: 8
ephemeral-storage: 47259264Ki
hugepages-2Mi: 0
memory: 30879764Ki
pods: 110
Allocatable:
attachable-volumes-gce-pd: 127
cpu: 7
ephemeral-storage: 18858075679
hugepages-2Mi: 0
memory: 29831188Ki
pods: 110
...
Capacity shows the total resources seen by Kubernetes in the machine, and
Allocatable shows the total resources allocated to user pods.
Resource requests and limits
Two concepts immediately appear in Kubernetes resource management: resource request and resource limit.
Resource request is taken into account by the scheduler for placing pods on
machines. As long as there is enough space in the resource allocated to the
user pods, the pod is assigned to a machine. Once the pod is assigned to a
machine, kubelet guarantees that the container can always use the requested
resource. “Pending” status means that the pod is waiting to be assigned. Every
pod’s lifecycle includes a “Pending” status; however, if a pod spends a long
time in this situation, it is useful to review its resource request. It
consists of the sum of the requests of the containers within the source request
of a pod.
It is crucial to define resource requests for each container to efficiently
benefit from user pods’ total resources. The scheduler checks whether the
machine’s available capacity is higher than the pods’ entire resource request
while assigning the pods. In practice, even if the pods in the machine consume
fewer resources than their request, if the sum of their requests is equal to
the available resources, no new pods are assigned to this machine. Because, as
I mentioned above, the source requested by the container is always guaranteed
by kubelet.
Resource limit is taken into account by kubelet to prevent a pod from consuming
all the system resources.
A container can consume more resources than it requests. However, if it consumes more memory than its request and the machine runs low on memory, it will be evicted.
What happens to a container that consumes more than its limit depends on the respective resource:
- If the memory limit is exceeded, the container can be terminated and restarted if possible.
- If the CPU limit is exceeded, the container is not terminated; only the CPU usage is throttled.
In practice, the total resource request of all containers on the machine cannot exceed the resource allocated to user pods; however, the sum of resource limits may be well above the available resources.
The total resource limit can exceed the maximum resource limit, just as the aircraft companies sell extra tickets and do overbooking. In this case, it will be more important to allocate resources for the system and Kubernetes processes, as I explained above.
Namespace level resource management
If you use Kubernetes namespaces to separate your services or environments (such as test, qa), you can set predefined resource requests and limits for each namespace. Therefore you can use default values for each container without configuring the resources separately.
For the default resource configuration, it is necessary to define a LimitRange:
apiVersion: v1
kind: LimitRange
metadata:
name: qa-limitrange
spec:
limits:
- default:
cpu: 1
memory: 512Mi
defaultRequest:
cpu: 500m
memory: 256Mi
type: Container
$ kubectl describe limits
Name: qa-limitrange
Namespace: qa
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu - - 500m 1 -
Container memory - - 256Mi 512Mi -
Since we are dealing with so many YAML files enough to experience minor crying
outbursts during the day, it is desirable to write four lines less in each
file. However, LimitRange does more than that. Especially in multi-tenant
Kubernetes clusters, we can define LimitRange to approve resource requests and
limits.
apiVersion: v1
kind: LimitRange
metadata:
name: dev-limitrange
spec:
limits:
- max:
cpu: 2
memory: 1Gi
min:
cpu: 1
memory: 500Mi
type: Container
$ kubectl describe limits
Name: dev-limitrange
Namespace: dev
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 500m 2 2 2 -
Container memory 256Mi 1Gi 1Gi 1Gi -
When we define LimitRange for a namespace, we create an admission controller,
enabling us to add any pod to the cluster after being approved in terms of
resource configuration before being accepted. Those who do not conform to the
LimitRange rules get rejected. This way, third parties, independent of the
system administrator, can install new pods without making other services
unstable.
Our control over namespace is not limited to this. We can also limit the total
resources of the namespace by defining a ResourceQuota.
apiVersion: v1
kind: ResourceQuota
metadata:
name: qa-resourcequota
namespace: qa
spec:
hard:
requests.cpu: "2"
requests.memory: 8Gi
limits.cpu: "2"
limits.memory: 8Gi
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: test-resourcequota
namespace: test
spec:
hard:
requests.cpu: "1"
requests.memory: 4Gi
limits.cpu: "1"
limits.memory: 4Gi
With the above configuration, we guarantee the following:
- The total memory request and limit of pods in Namespace cannot exceed 8 GB for qa and 4 GB for testing.
- The total CPU request and limit of pods in Namespace cannot exceed 2 CPUs for qa and 1 CPU for testing.
QoS classes
The QoS (Quality of Service) classes belonging to pods are essential for both scheduling and eviction. There are three classes of QoS we can use:
- Guaranteed: If the resource requests and limits of all containers within the pod are equal.
- Burstable: Pod does not classify as Guaranteed and requests at least one container resource.
- BestEffort: If no container in the pod has any resource requests or limits.
As you can see, these classes are assigned by Kubernetes based on pods’ source configuration.
$ kubectl get pod <pod> -o yaml
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: container-1
image: ...
resources:
limits:
memory: 1Gi
requests:
cpu: 100m
memory: 512Mi
status:
...
phase: Running
qosClass: Burstable
Eviction
Despite all the configurations I explained above, our machines’ resources may
run out, and the cluster may become unstable. In this case, kubelet will try to
recover resources quickly. If their efforts are futile, eviction process
begins.
For eviction, kubelet puts the pods in a row:
Those pods belonging to BestEffort or Burstable QoS classes, which use more than request sources from pods, are ranked according to their priorities and how much resources they consume out of their requests, and are evicted. Guaranteed pods and Burstable pods that consume fewer resources than their requests are evicted the last. As their name suggests, Guaranteed pods are assured that they will be not be evicted due to other pods’ resource consumption. However, if the resources allocated to the system or Kubernetes start to run out, they can also be evicted, beginning with the lowest priority pod.
Priority is a value that we can set with PriorityClass, again as Kubernetes
administrators. In order not to complicate this blog post further, I end it
here after sharing relevant documents.
This post is originally published in Kartaca’s blog. Thanks to lovely Gizem for editing and translating the text.